
Der SEO Low Hanging Fruits Index
Seiten mit hohem SEO Potential identifizieren
Fortgeschritten
Voraussetzung:
- Sistrix Modul SEO
- Screaming Frog
- MS Excel
Diese starke Methodik in der kontinuierlichen Optimierung einer Website ist die Identifikation sogenannter Low Hanging Fruits. Der Begriff Low Hanging Fruits kommt aus der Betriebswirtschaftslehre, insbesondere dem Marketing, und bezeichnet Aufgaben, die mit relativ geringem Aufwand ein relativ gutes Ergebnis liefern. Diese Aufgaben sollten nach dem Pareto Prinzip eine hohe Priorität haben.
In der Suchmaschinenoptimierung gehören Schwellenkeywords und die anschließenden gezielten Maßnahmen der Onpage Optimierung zu den Low Hanging Fruits. Schwellenkeywords sind relevante Keywords mit Rankings einer URL im Bereich zwischen beispielsweise 8 und 30. Das Ziel ist die Verbesserung der Rankings dieser Keywords in traffic-relevante Positionen.
Im Folgenden erläutere ich eine Methode inklusive eines Index (den ich LHF-Index getauft habe), die ich in meiner täglichen Arbeit zur Verbesserung der Rankings meiner Kunden nutze und so die definierten Ziele effizienter erreiche.
Benötigt werden die folgenden Tools, die zum Arbeitswerkzeug der meisten SEOs gehören:
- der Crawler Screaming Frog
- Das SEO Modul von Sistrix
- die Tabellenkalkulation MS Excel
Die verschiedenen Arbeitsschritte und Aufgaben zeige ich am Beispiel des Blogs & Shops rapantinchen.de.
Per Screaming Frog Crawl Inhalte extrahieren
Im ersten Schritt werden die wichtigsten Inhalte, nämlich der Title Tag, die <Hx> Überschriften und die Texte extrahiert.
Zu diesen Zweck crawle ich die Seite per Screaming Frog mit einer Custom Extraction:
Im Menü: Configuration > Custom > Extraction
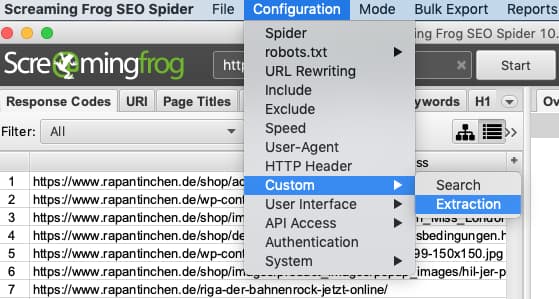
Als nächstes werden die Parameter für die custom extraction eingegeben. Grundlage für die folgende Konfiguration ist, dass die relevanten Textelemente im <body> der Website ordnungsgemäß mit dem <p> Tag beginnen.
Ich benenne den jeweiligen Extractor, so dass ich die richtige Spalte später im Crawl auch wiederfinde. Anschließend wähle ich noch XPath mit den Elementen //title; //h1; //h2 und //p und der Option Extract Text als Extraktionsmethode aus.
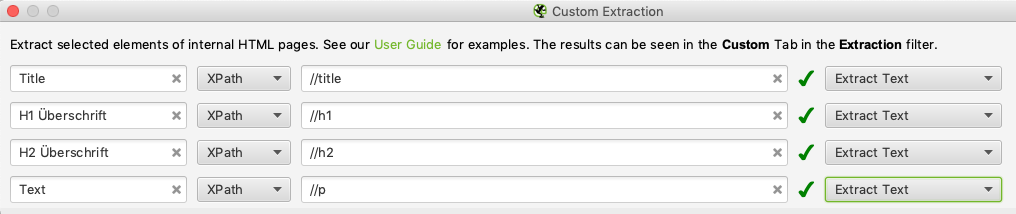
Nun wird der Crawl gestartet und je nach Größe der Website und Rechnerkapazität erst mal ein Tee (oder wahlweise Kaffee) getrunken.
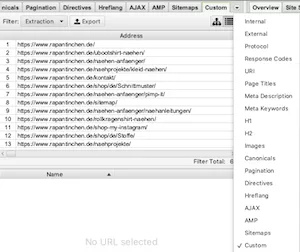 Ist der Crawl fertig, exportiere ich die Ergebnisse des Custom Crawls, in dem ich im Reiter Custom mit dem Filter Extraction auf Export klicke.
Ist der Crawl fertig, exportiere ich die Ergebnisse des Custom Crawls, in dem ich im Reiter Custom mit dem Filter Extraction auf Export klicke.
Die .xls Datei speichere ich für die spätere Verwendung.
Schwellenkeywords URLs mit Sistrix identifizieren
Im nächsten Schritt identifiziere ich Seiten, die mit Keywords auf Schwellenpositionen ranken. Als Schwellenposition definiere ich Positionen zwischen 8 und 50 sowie ein Suchvolumen (laut Sistrix) von mindestens 20. Diese Parameter können natürlich je nach Projekt und eigenen Präferenzen angepasst werden.
Im Sistrix SEO Modul werden die Keywords entsprechend mit Positionen und Suchvolumen identifiziert.
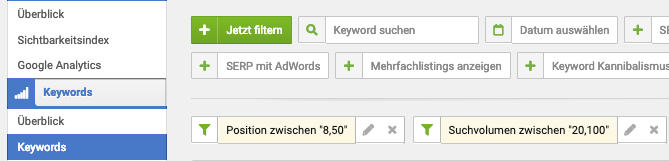
Das Ergebnis wird exportiert und für die spätere Verwendung gespeichert.
Aufbereiten der Daten in Excel
Nun kommt die eigentliche Arbeit. Wir müssen die Daten aufbereiten und verknüpfen.
Ich öffne die Export .xls-Datei der custom extraction des Screaming Frog.
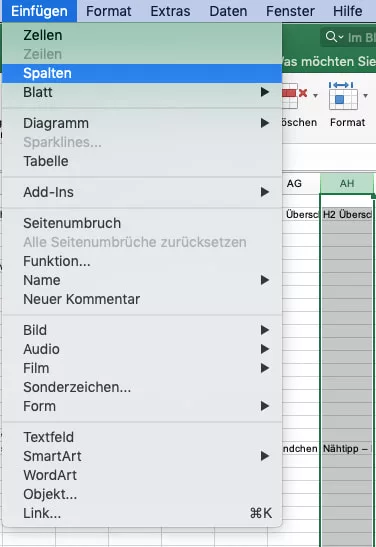
In der Excel Datei wurde für jedes Title, <Hx> oder <P> Element eine Spalte angelegt. Diese Spalten müssen nun in jeweils einer Spalte zusammen gefasst werden. Zu diesem Zweck klicke ich auf die letzte Spalte des jeweiligen Elements und füge eine leere Spalte ein. Hier gezeigt am Beispiel der <H2> Überschriften.
In der leeren Spalte fasse ich die Inhalte der Spalten der jeweiligen Elemente (Title, <Hx> Überschriften oder Texte) mithilfe der folgenden Excel Formel zusammen:
=P3&" "&Q3&" "&R3&" "&S3&" "&T3&" "&U3&" "&V3&" "&W3&" "&X3&" "&Y3&" "&Z3&" "&AA3&" "&AB3&" "&AC3&" "&AD3&" "&AE3&" "&AF3&" "&AG3
Hier muss natürlich darauf geachtet werden, dass die Spaltenbezeichnungen in der Formel zu den Inhalten der Spalten passen. In der Zelle der Spalte sollten nun alle Inhalte der Spalten mit <h2> Elementen zusammen gefasst sein. Diese Formel ziehen wir nun bis zur letzten Zeile der Tabelle.
Diese Vorgehensweise wiederhole ich nun für alle Spalten mit den extrahierten Tags (<h1>; <h2> und <p>). Hier als kleine Arbeitserleichterung die Formeln, um die Spalten zusammenfassen bis zur Spalte EZ3. Einfach den jeweils benötigten Teil raus kopieren und in die Excel Spalte eintragen.
Weiter geht es mit einer neuen Excel-Tabelle. Du kannst diese selber anlegen oder meine Excel Vorlage verwenden.
Falls Du die Tabelle selbst anlegen möchtest, ist es wichtig, dass Du Spalten und Tabellen genau so sortierst und benennst, wie hier vorgeschlagen.
![]() Im ersten Schritt legst Du zwei Tabellenblätter an: LHF Index und Screaming Frog Extraction
Im ersten Schritt legst Du zwei Tabellenblätter an: LHF Index und Screaming Frog Extraction
Im Tabellenblatt LHF Index legst Du folgende Spalten an: Keyword; URL; Position; Suchvolumen; Wettbewerb; Keyword im Text; Keyword im Title; Keyword in H1; Keyword in H2; LHF Index

In den Spalten Keyword im Text; Keyword im Title; Keyword in H1; Keyword in H2; LHF Index müssen noch in der zweiten Zeile die Formel eingefügt werden:
- Keyword im Title: =WENNFEHLER(SUCHEN(A2;(SVERWEIS(C2;'Screaming Frog Extraction'!A:B;2;FALSCH)));"KW not in <TITLE>")
- Keyword in H1: =WENNFEHLER(SUCHEN(A2;(SVERWEIS(C2;'Screaming Frog Extraction'!A:C;3;FALSCH)));"KW not in <H1>")
- Keyword in H2: =WENNFEHLER(SUCHEN(A2;(SVERWEIS(C2;'Screaming Frog Extraction'!A:D;4;FALSCH)));"KW not in <H2>")
- Keyword in Text: =WENNFEHLER(SUCHEN(A2;(SVERWEIS(C2;'Screaming Frog Extraction'!A:E;5;FALSCH)));"KW not in <P>")
- LHF Index: =((((WENN($F2="KW not in <TITLE>";16;0))+(WENN($G2="KW not in <H1>";8;0))+(WENN($H2="KW not in <H2>";4;0))+(WENN($I2="KW not in <P>";2;0)))/2)*(WENN(B2<=10;B2+1;B2*(-1/4)+12,5))*(-0,125*E2+12,5)*(((D2)/10)^2))^0,5
Der LHF-Index wird im nächsten Kapitel erklärt.
Im Tabellenblatt Screaming Frog Extraction legst Du folgende Spalten an: Address; Title 1; H1 Überschriften; H2 Überschriften; P Text![]()
Alternativ nutzt Du meine Vorlage 😉
Nun kopiere ich die Spalten Keyword; Position; URL; Suchvolumen; Wettbewerb aus der Sistrix Exportdatei in den entsprechenden Spalten in dem Tabellenblatt LHF Index.
 Im nächsten Schritt kopiere ich die zusammengefassten Spalten (<h1>; <h2> und <p>) der Export .xls-Datei der custom extraction des Screaming Frog in die jeweils passenden Spalten in das Tabellenblatt Screaming Frog Extraction. Dabei ist zu beachten, dass die Inhalte in Excel über Bearbeiten - Inhalte einfügen - Werte eingefügt werden.
Im nächsten Schritt kopiere ich die zusammengefassten Spalten (<h1>; <h2> und <p>) der Export .xls-Datei der custom extraction des Screaming Frog in die jeweils passenden Spalten in das Tabellenblatt Screaming Frog Extraction. Dabei ist zu beachten, dass die Inhalte in Excel über Bearbeiten - Inhalte einfügen - Werte eingefügt werden.
Nun habe ich alle Werte in meiner Excel Tabelle. Nun ziehe ich die Spalten F,G,H;I;J mit Formeln bis zur letzten Zeile mit Werten.
Nun kann ich meine Liste anhand des LHF-Index sortieren und priorisieren. Mehr zum LHF Index im nächsten Kapitel.
Der LHF-Index
SEOs mögen Indizes! Um die Ergebnisse der Low Hanging Fruits Analyse besser priorisieren zu können, fehlte noch ein entsprechender Index. Zum Glück habe ich den Physiker Niels Lange in meinem Freundeskreis, der mir bei der Entwicklung des LHF-Index geholfen hat. Im Folgenden wird der LHF-Index erklärt und so kann jeder die Parameter gegebenenfalls anpassen.
Der LHF-Index ist von folgenden Parametern abhängig, die in der folgenden Erklärung und in der Formel des LHF-Index verwendet werden:
T: kommt das Keyword nicht im Title vor, ist T = 1, sonst 0
H1: kommt das Keyword nicht in einer H1 Überschrift vor, ist H1 = 1, sonst 0
H2: kommt das Keyword nicht in einer H2 Überschrift vor, ist H2 = 1, sonst 0
P: kommt das Keyword nicht im Text vor, ist P = 1, sonst 0
R: entspricht der Position im Google Suchergebnis
V: steht für das Suchvolumen laut Sistrix
W: ist der Wettbewerb laut Sistrix
Die Formel des LHF-Index sieht dann so aus:

Die Werte für T, H1, H2 und P werden summiert und dabei mit einem Faktor gewichtet. Die Faktoren sind danach gewählt, wie relevant das Vorkommen des Suchbegriffes im entsprechenden Bereich der Webseite (Title, H1, H2, Text) für die Position der Webseite in Googles Suchergebnis ist. Die gewählten Gewichte (8, 4, 2, 1) gehen von einer jeweils doppelt so hohen Relevanz aus. Damit wird ein Vorkommen im Title achtmal so hoch bewertet wie ein Vorkommen im Text.
Die so berechnete Summe wird mit drei Faktoren multipliziert, deren Werte sich mittels dreier einfacher Funktionen bestimmen lassen.
f(R) ist abschnittsweise durch zwei lineare Funktionen definiert, im ersten Abschnitt mit positiver Steigung, im zweiten Abschnitt mit negativer. Dadurch steigt der Wert von f(R) für R von 1 bis 10 und fällt zwischen 11 und 50 wieder ab. Dies bewirkt eine höhere Gewichtung der URLs, die um die Position 10 im Suchergebnis auftauchen.
g(W) ist als einfache lineare Funktion mit negativer Steigung definiert, d.h. je größer der Wettbewerb ist, desto geringer wird g(W) und damit auch der LHF Wert. URLs deren Suchbegriffe einem geringen Wettbewerb unterliegen werden somit für die Optimierung bevorzugt ausgewählt, da sie einen höheren LHF Wert erhalten.
h(V) hängt vom Quadrat des Suchvolumens ab, d.h. eine Verdoppelung des Suchvolumens führt zu einer Vervierfachung von h(V). Diese Abhängigkeit spiegelt die enorme Bedeutung des Suchvolumens bei der Auswahl der zu optimierenden Seiten wieder.
Das Gesamtergebnis des LHF wird hier als Wurzel aus dem gerade beschriebenen Produkt gebildet. Dies hat nur kosmetisch Gründe, da der Wertebereich des LHF so auf Werte zwischen 0 und unter 100 verkleinert wird.
Die Funktionen und Faktoren sind so gewählt, dass die verschiedenen Parameter ausgewogen in den Gesamtwert einfließen. Dadurch können unterschiedliche Konstellationen zu einem hohen LHF Wert führen. Z.B. kann ein hohes Suchvolumen eine schlechte Ausgangsplatzierung ausgleichen. Die hier gezeigten Funktionen und Faktoren sind jedoch sicher nicht für jeden Anwendungsfall optimal und sollen daher vielmehr als Inspiration dienen, wie ein LHF Index berechnet werden kann.
Probiert es einfach aus und variiert die Funktionen! Viel Spaß dabei. Feedback und Anregungen sind willkommen.
